
Choosing Your Champion: A New Playbook for Vetting AI in Digital Health

The integration of artificial intelligence into healthcare has moved from a futuristic vision to a present-day reality. With a staggering 85% of healthcare leaders actively investing in generative AI, the technology is poised to redefine clinical efficiency and patient care (Zoho, 2025). Yet, for every advance, a critical question looms larger: can we trust the output? This is not just about preventing factual errors; it's about ensuring that AI tools are precise, reliable, and safe for high-stakes medical use.
Initially, the challenge was grounding AI in credible sources. Frameworks like "Answered with Evidence" provided a foundational "traffic light" system to verify if an AI's response was supported by evidence at all (Baldwin et al., 2025). But the industry is rapidly maturing. It’s no longer enough to know if an AI is evidence-based. The crucial next question is: which AI is the right tool for a specific, complex job?
A new study introducing the RWESummary framework provides the answer. It offers a sophisticated playbook for benchmarking and selecting the best Large Language Models (LLMs) for the nuanced task of summarizing real-world evidence (RWE), revealing critical performance differences among today's leading AI models (Mukerji et al., 2025).
From Grounding to Precision: The Evolution of AI Evaluation

The first step in building trust was ensuring AI responses were not fabricated. The "Answered with Evidence" framework established a baseline by evaluating whether an AI's answer was directly supported by, or at least related to, a provided evidence source (Baldwin et al., 2025). This was a vital guardrail against hallucination.
However, real-world clinical data—drawn from messy electronic health records and complex databases—presents a far greater challenge than summarizing a clean research paper. The data is structured, dense with numbers, and the clinical implications are profound. An error in summarizing this data could have serious consequences.
This is where the RWESummary framework comes in. Developed by researchers at Atropos Health, it is designed specifically to test an LLM's ability to accurately interpret and summarize structured RWE study results. It moves beyond general grounding to measure precision across three critical domains:
Direction of Effect: Does the summary correctly report whether a treatment was beneficial, harmful, or had no effect? The authors argue this is the most critical metric, as misstating a drug's effect direction would be a catastrophic error3.
Accurate Numbers: Are all the figures in the summary—like patient counts, p-values, and effect estimates—correctly reported from the source data?
Completeness: Does the summary include all the meaningful outcomes from the original study, especially those that are statistically significant?
To ensure objectivity, the framework uses a "three-member LLM jury"—comprising models from OpenAI, Anthropic, and Google—to grade each summary, a sophisticated method for reducing single-model bias.
The Head-to-Head Comparison: Which AI Models Excel?
The researchers used RWESummary to benchmark nine leading LLMs from Google (Gemini), Anthropic (Claude), and OpenAI (GPT models) on their ability to summarize 13 distinct RWE studies. The results were incredibly revealing, demonstrating that performance is anything but uniform. While all models were generally successful at including the most important outcomes (Completeness scores from 0.82 to 1.0), there was significant variability in their precision.
Key Performance Highlights:
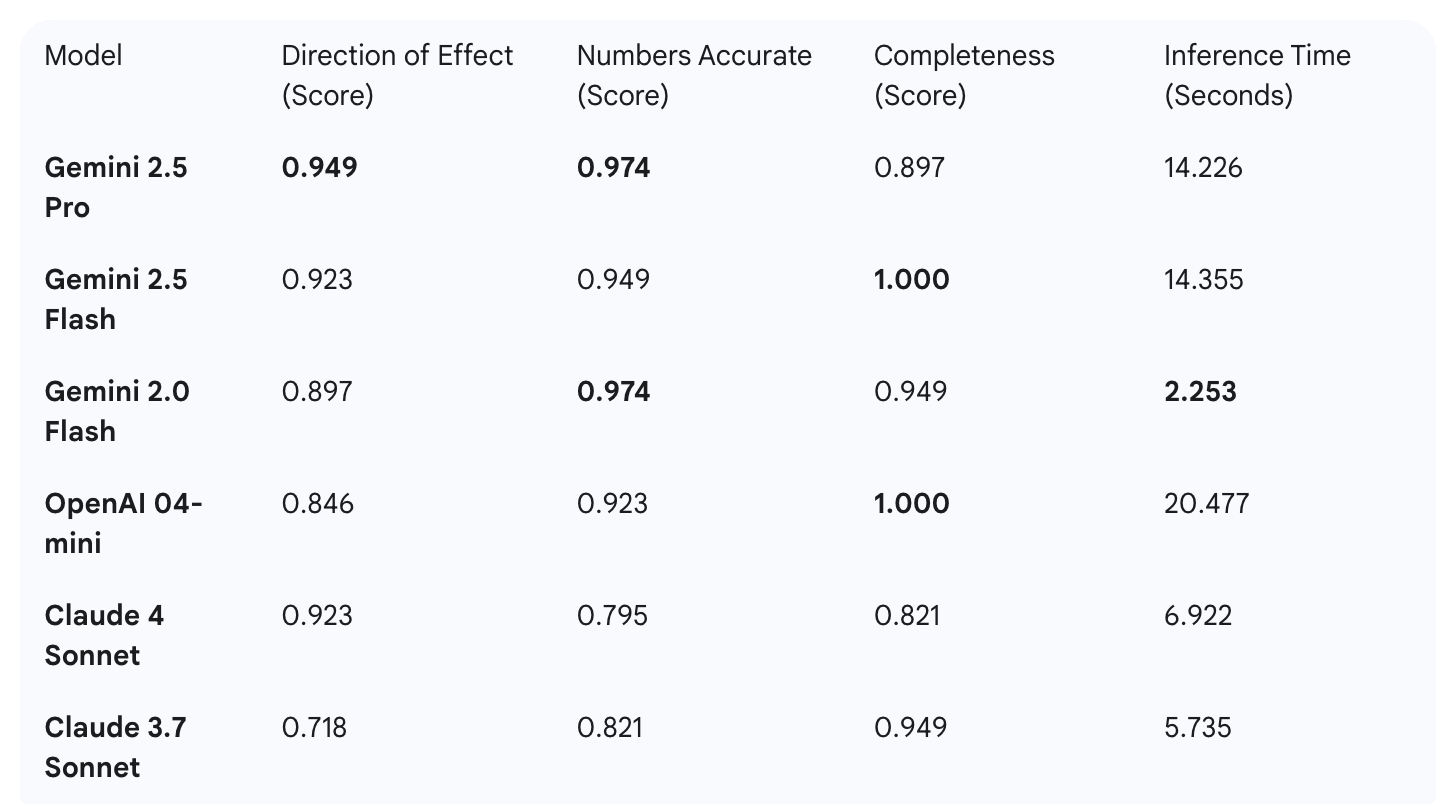
As the data shows, no single model was the best across all categories.
Precision Kings: Gemini 2.5 Pro and Gemini 2.0 Flash were the top performers on numeric accuracy, while Gemini 2.5 Pro was the best at correctly identifying the direction of effect.
Completeness Champions: Gemini 2.5 Flash and OpenAI's 04-mini and o3 models achieved perfect scores for including all important outcomes.
The Need for Speed: Gemini 2.0 Flash was by far the fastest model, generating summaries in just 2.2 seconds on average.
Recognizing that different applications have different priorities, the study proposes a weighted scoring rubric. This allows an organization to decide what matters most—is it flawless accuracy or rapid generation time? When researchers applied a sample weighting that prioritized effect direction and accuracy, the Gemini models (2.5 Pro, 2.5 Flash, and 2.0 Flash) emerged as the clear front-runners. However, they note that if speed were weighted more heavily, Gemini 2.0 Flash would become the preferred model.
Takeaways for the Digital Health Community
This research provides a clear-eyed view of the current LLM landscape and offers crucial lessons for anyone building or deploying AI in healthcare:
There is No "Model to Rule Them All": The study powerfully concludes that the best model is context-dependent. Organizations must move beyond marketing hype and conduct rigorous, task-specific testing to find the right tool for their needs.
Task-Specific Benchmarking is Non-Negotiable: General capabilities on medical exams are interesting, but they do not predict performance on specialized tasks like RWE summarization. The RWESummary framework provides a blueprint for this essential due diligence.
Prioritize What Matters: The concept of a weighted rubric is a critical takeaway for product leaders and health systems. A model used for generating patient-facing educational content might prioritize simplicity and speed, while one summarizing evidence for a clinical decision support tool must prioritize accuracy and direction of effect above all else.
The Path Forward: A Call for Rigor and Collaboration
The journey to integrate AI into healthcare is a marathon, not a sprint. Frameworks like "Answered with Evidence" and "RWESummary" provide the essential tools to navigate this journey safely and effectively. They empower the digital health community to move from hope to proof, ensuring that the AI tools we deploy are not only powerful but also precise, reliable, and worthy of our trust.
These are precisely the conversations that need to happen now, across the industry. The upcoming CTeL Digital Health Tech and AI Showcase on September 23rd in Washington D.C. is a vital forum for these discussions. It will bring together the innovators, providers, and policymakers who must work together to set the standards for the next generation of healthcare technology. By embracing rigorous, evidence-based evaluation, we can collectively ensure that AI fulfills its promise to revolutionize care.
References
Baldwin, J. D., Dinh, C., Mukerji, A., Sanghavi, N., & Gombar, S. (2025). Introducing Answered with Evidence - a framework for evaluating whether LLM responses to biomedical questions are founded in evidence. medRxiv.
Mukerji, A., Jackson, M. L., Jones, J., & Sanghavi, N. (2025). RWESummary: A Framework and Test for Choosing Large Language Models to Summarize Real-World Evidence (RWE) Studies. arXiv.
Zoho. (2025). 10 digital trends that are shaping digital healthcare in 2025. Retrieved from Zoho healthcare trends.